
Apscheduler源码剖析-Scheduler(1)-Job篇
本章节主要讲解调度器的任务相关API
调度器(scheduler)是整个apscheduler的重中之重。光从命名上就能看得出来它的地位。因为它就像大脑,掌控和指挥着各个功能之间的衔接。任务添加/暂停/启动、何时触发、如何存储任务、谁来执行任务、执行事件通知等等...都是由这个调度器来分发的。
我们再次回到原点,看看想要创建并启动一个任务的样子:
trigger = IntervalTrigger(days=1, start_date='2022-08-01')
scheduler.add_job(print_something, trigger)
scheduler.start()
前面几章,我们一起把触发器捋了一遍,知道了最为核心的方法get_next_fire_time。通过调用它来计算任务下一次执行的时间。不同的触发器只是约束了不同的规则,从而更改触发策略。
接下来我将从调度器的添加任务(也就是上面源码的第二行)开始展开对调度器的解析。
创建任务-add_job
def add_job(self, func, trigger=None, args=None, kwargs=None, id=None, name=None,
misfire_grace_time=undefined, coalesce=undefined, max_instances=undefined,
next_run_time=undefined, jobstore='default', executor='default',
replace_existing=False, **trigger_args):
# trigger触发器可以通过alias别名或者是实例来给job指定
job_kwargs = {
# self._create_trigger来创建trigger实例
'trigger': self._create_trigger(trigger, trigger_args),
'executor': executor,
'func': func,
'args': tuple(args) if args is not None else (),
'kwargs': dict(kwargs) if kwargs is not None else {},
'id': id,
'name': name,
'misfire_grace_time': misfire_grace_time,
'coalesce': coalesce,
'max_instances': max_instances,
'next_run_time': next_run_time
}
# 过滤掉undefined的参数
job_kwargs = dict((key, value) for key, value in six.iteritems(job_kwargs) if
value is not undefined)
# 创建job实例
job = Job(self, **job_kwargs)
# Don't really add jobs to job stores before the scheduler is up and running
with self._jobstores_lock:
if self.state == STATE_STOPPED:
# 如果当前状态已经暂停了,但是任务添加了,那就把任务添加到缓存中
self._pending_jobs.append((job, jobstore, replace_existing))
self._logger.info('Adding job tentatively -- it will be properly scheduled when '
'the scheduler starts')
else:
# 将任务加入到jobstore中,替换已存在的
self._real_add_job(job, jobstore, replace_existing)
return job
添加任务的代码从表项看十分简单,就是将参数传入Job类,生成job实例后加入jobstore中再返回当前job实例。
其中比较有意思的方法是_create_trigger,通过它可以将外部传来的字符串trigger别名转为触发器实例。
_create_trigger
def _create_trigger(self, trigger, trigger_args):
# 查看传入的触发器是不是BaseTrigger的实例
if isinstance(trigger, BaseTrigger):
return trigger
# 当没有指定的时候,使用默认的触发器:'date'
elif trigger is None:
trigger = 'date'
# 检查是否是字符串
elif not isinstance(trigger, six.string_types):
raise TypeError('Expected a trigger instance or string, got %s instead' %
trigger.__class__.__name__)
# Use the scheduler's time zone if nothing else is specified
trigger_args.setdefault('timezone', self.timezone)
# 实例化触发器
return self._create_plugin_instance('trigger', trigger, trigger_args)
再次进入到_create_plugin_instance中。
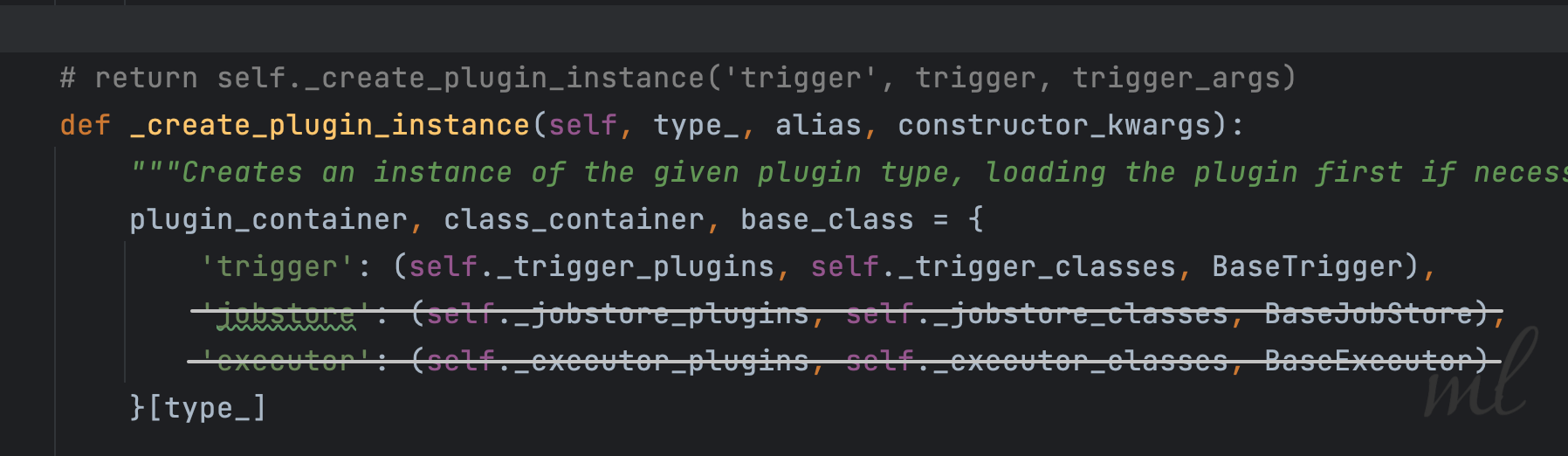
由于_create_plugin_instance传来的是 'trigger', trigger, trigger_args 所以我们不需要关注jobstore和executor,但是我们要清楚,jobstore和executor也是通过_create_plugin_instance来创建的。
上图中:
plugin_container, class_container, base_class
对应的就是:
self._trigger_plugins, self._trigger_classes, BaseTrigger
_create_plugin_instance
def _create_plugin_instance(self, type_, alias, constructor_kwargs):
"""Creates an instance of the given plugin type, loading the plugin first if necessary."""
plugin_container, class_container, base_class = {
'trigger': (self._trigger_plugins, self._trigger_classes, BaseTrigger),
'jobstore': (self._jobstore_plugins, self._jobstore_classes, BaseJobStore),
'executor': (self._executor_plugins, self._executor_classes, BaseExecutor)
}[type_]
try:
# 通过别名来映射到对应的类,优先通过缓存`_trigger_classes`中来获取
plugin_cls = class_container[alias]
except KeyError:
# 如果没找到,则从内置插件中获取
if alias in plugin_container:
# 从内置插件中获取,并且加入class_container中
plugin_cls = class_container[alias] = plugin_container[alias].load()
if not issubclass(plugin_cls, base_class):
raise TypeError('The {0} entry point does not point to a {0} class'.
format(type_))
else:
raise LookupError('No {0} by the name "{1}" was found'.format(type_, alias))
# 返回实例化后的对象
return plugin_cls(**constructor_kwargs)
所谓别名获取类实例,其实是先通过字典约束好键值对,通过trigger字符串找到对应的值:
'trigger': (self._trigger_plugins, self._trigger_classes, BaseTrigger)
问题在于_trigger_plugins从哪来?这得追溯到类的最顶端:
_trigger_plugins = dict((ep.name, ep) for ep in iter_entry_points('apscheduler.triggers'))
_trigger_classes = {}
触发器插件是通过iter_entry_points('apscheduler.triggers')来获取的。
这得了解下模块pkg_resources的使用。
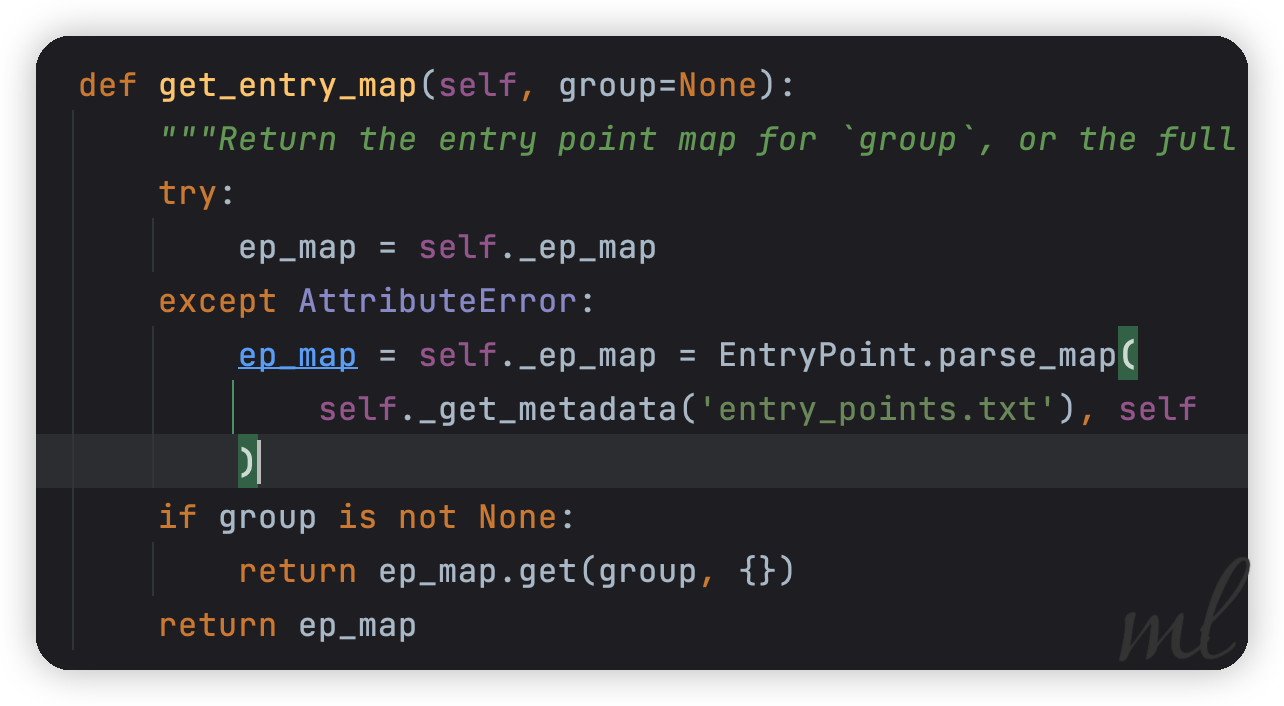 默认读取的是模块包下的
默认读取的是模块包下的entry_points.txt文件。
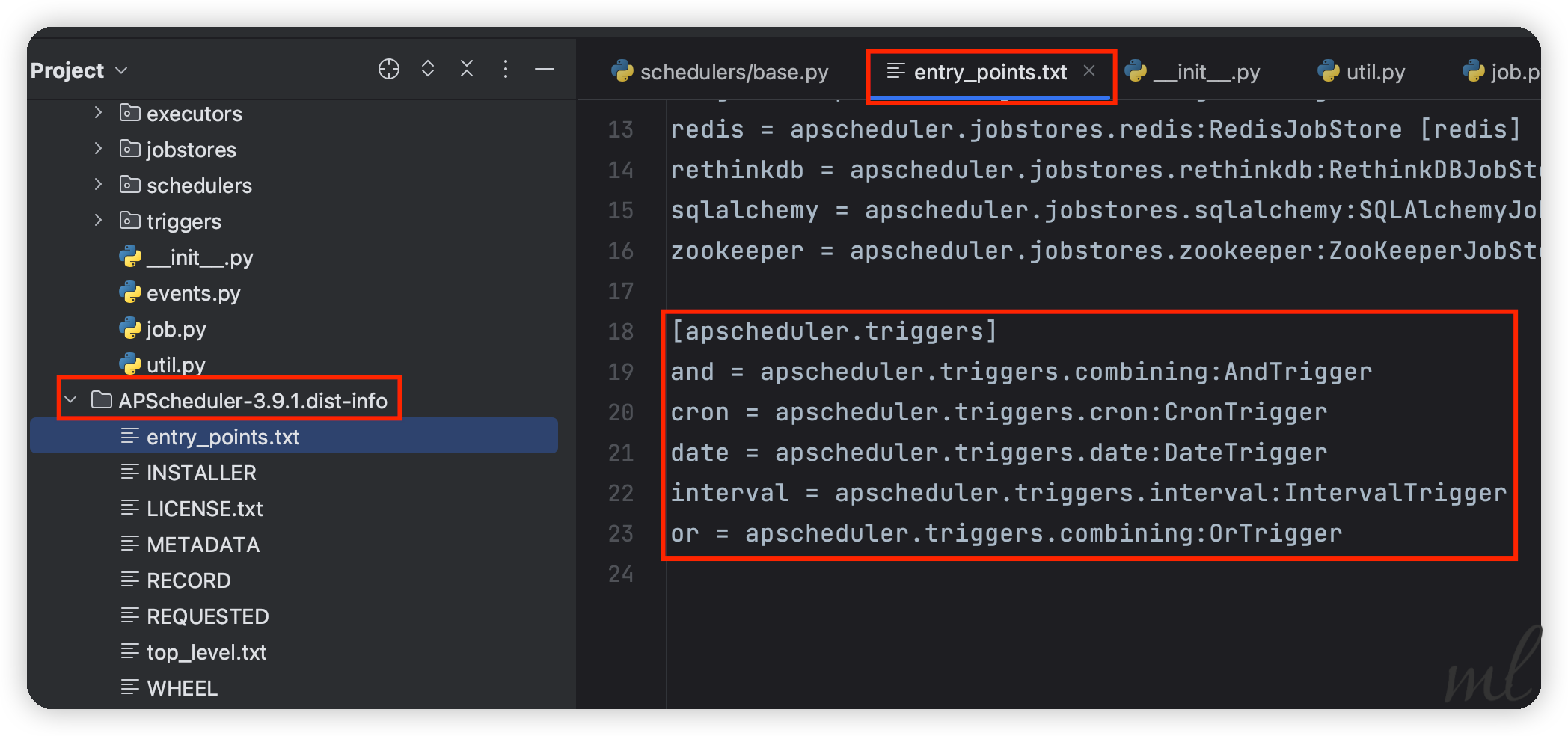
为了印证结果,我在这个文件下,加入我之前写的CrontabTrigger触发器:
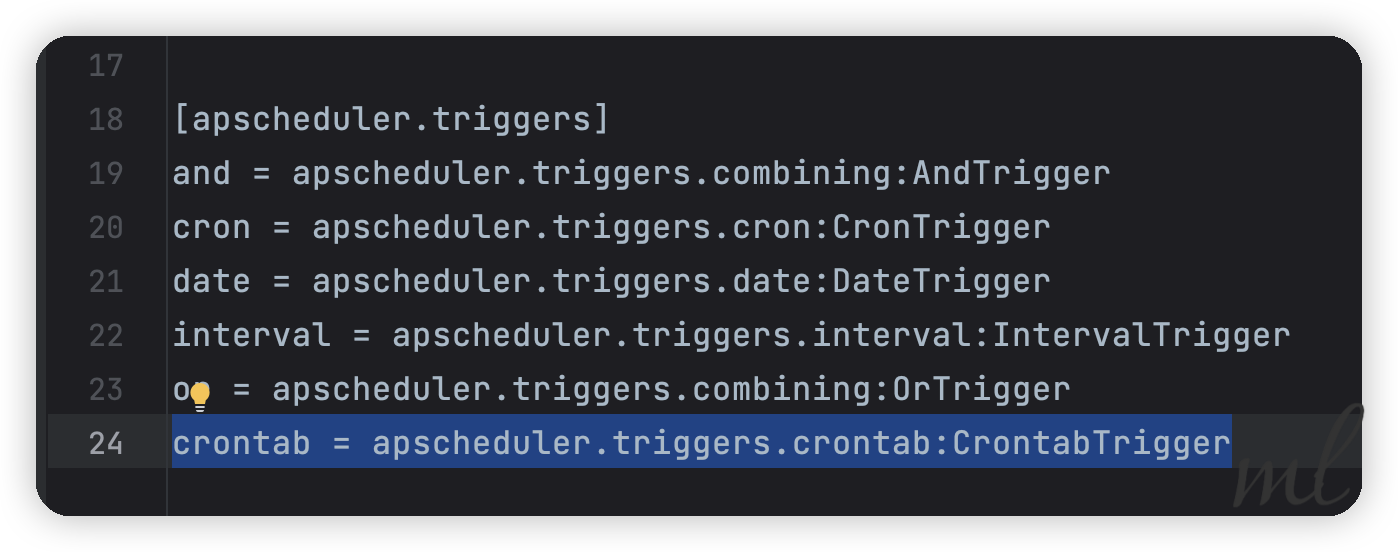
然后在add_job的时候给定字符串触发器:
scheduler.add_job(print_something, trigger="crontab")
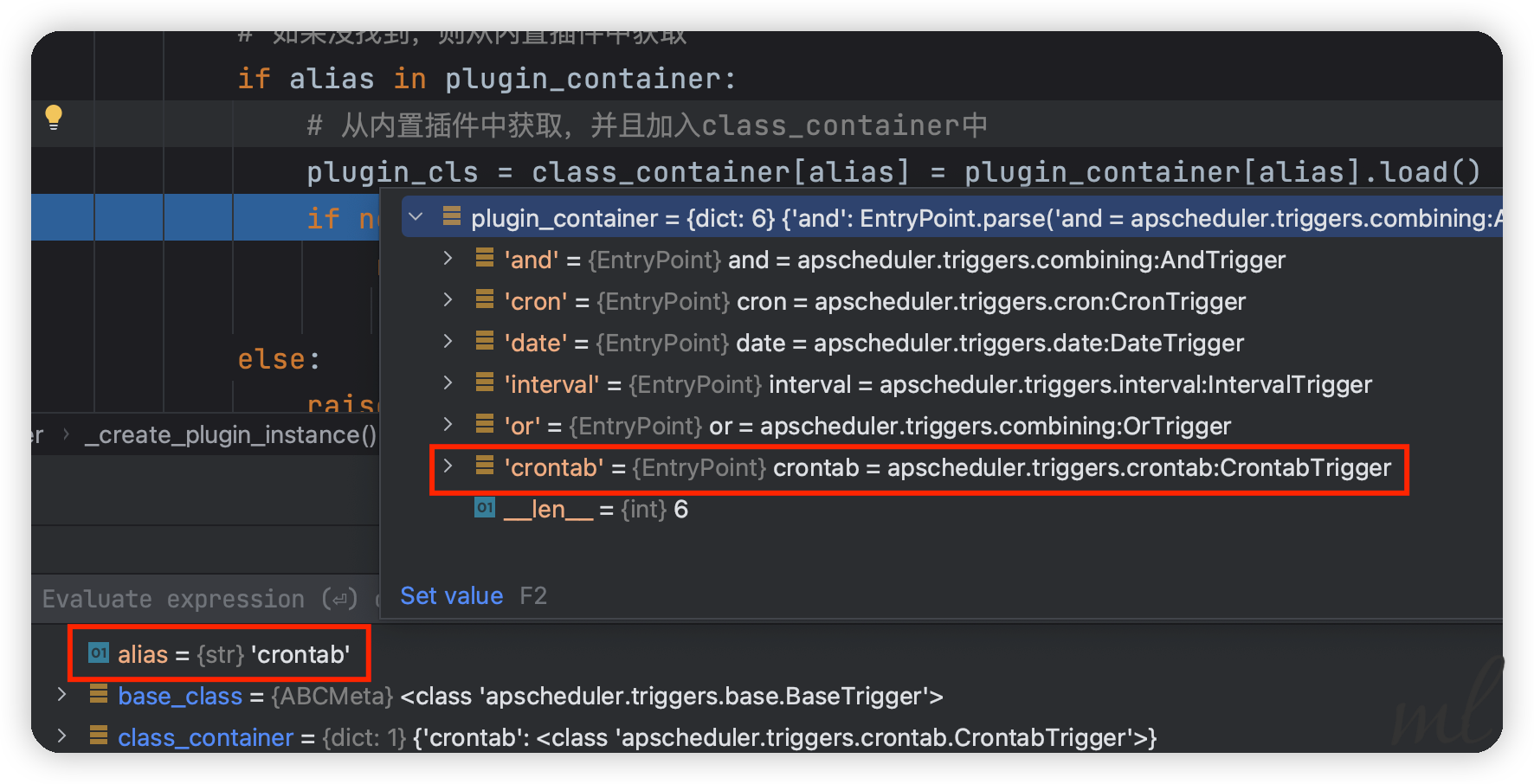
可以看到,使用字符串触发器加载自定义的触发器成功了~
有了任务的新增,就会有任务的增删改查……,就任务而言,继续看看任务在调度器中是如何操作的。
修改任务-modify_job
def modify_job(self, job_id, jobstore=None, **changes):
with self._jobstores_lock:
# 通过job_id找到job
job, jobstore = self._lookup_job(job_id, jobstore)
# 修改任务的属性
job._modify(**changes)
if jobstore:
# 如果有jobstore,那就把任务修改到jobstore中
# 此处的`update_job`会调用jobstore的update_job方法
# 这里的jobstore可以是memory、mongodb、redis等等
self._lookup_jobstore(jobstore).update_job(job)
# 发送修改事件
self._dispatch_event(JobEvent(EVENT_JOB_MODIFIED, job_id, jobstore))
if self.state == STATE_RUNNING:
# 重新唤醒任务调度器
self.wakeup()
# 返回修改后的任务
return job
_lookup_job
def _lookup_job(self, job_id, jobstore_alias):
if self.state == STATE_STOPPED:
# 如果当前状态是暂停的,从缓存任务中获取
for job, alias, replace_existing in self._pending_jobs:
if job.id == job_id:
return job, None
else:
# 从所有的jobstore中查找
for alias, store in six.iteritems(self._jobstores):
if jobstore_alias in (None, alias):
# 这里的`store`指的是任意指定的`jobstore`
job = store.lookup_job(job_id)
if job is not None:
return job, alias
raise JobLookupError(job_id)
job._modify任务的实际修改,放在后面job的文章中讲解。
_lookup_jobstore
def _lookup_jobstore(self, alias):
# 实际就是从`_jobstores`通过别名找出任务存储的类。
try:
return self._jobstores[alias]
except KeyError:
raise KeyError('No such job store: %s' % alias)
暂停任务-pause_job
看完修改任务后,暂停任务就变得十分简单,其原理就是修改任务,将任务的下一次执行时间设置为None。
def pause_job(self, job_id, jobstore=None):
return self.modify_job(job_id, jobstore, next_run_time=None)
恢复任务-resume_job
恢复任务最重要的就是要将任务的下一次运行时间同当前时间做一次计算,把得到的时间再进行对任务修改实现恢复。
def resume_job(self, job_id, jobstore=None):
with self._jobstores_lock:
# 找到任务
job, jobstore = self._lookup_job(job_id, jobstore)
# 计算下一次运行时间
now = datetime.now(self.timezone)
next_run_time = job.trigger.get_next_fire_time(None, now)
if next_run_time:
# 如果满足,则修改任务的下一次运行时间
return self.modify_job(job_id, jobstore, next_run_time=next_run_time)
else:
# 否则,删除这个任务
self.remove_job(job.id, jobstore)
删除任务-remove_job
从jobstore中找到指定job_id后删除
def remove_job(self, job_id, jobstore=None):
jobstore_alias = None
with self._jobstores_lock:
# Check if the job is among the pending jobs
if self.state == STATE_STOPPED:
# 如果当前任务是暂停状态,遍历缓存中的任务,发现指定job_id就删除
for i, (job, alias, replace_existing) in enumerate(self._pending_jobs):
if job.id == job_id and jobstore in (None, alias):
del self._pending_jobs[i]
jobstore_alias = alias
break
else:
# Otherwise, try to remove it from each store until it succeeds or we run out of
# stores to check
# 遍历jobstore
for alias, store in six.iteritems(self._jobstores):
if jobstore in (None, alias):
try:
# 从jobstore中删除
store.remove_job(job_id)
jobstore_alias = alias
break
except JobLookupError:
continue
if jobstore_alias is None:
raise JobLookupError(job_id)
# 发送删除事件
event = JobEvent(EVENT_JOB_REMOVED, job_id, jobstore_alias)
self._dispatch_event(event)
self._logger.info('Removed job %s', job_id)
计划任务-scheduled_job
它实际上是add_job的一个装饰器,用于装饰需要执行的函数。