
python中命令行的应用实践
起源
小k是一家互联网公司的爬虫(cv)工程师,他在这家公司写过大大小小无数个爬虫脚本。有一天他打开自己写过的一个爬虫项目,看到密密麻麻几十个网站的spider文件,内心暗喜,”我真是个人才,居然能写出这么多优秀且稳定的代码“。忍不住得将项目截图发给小m,等待着即将回复的:”卧槽牛逼啊“,但随即等来的却是一句:”你这么多爬虫文件,你怎么运行的?“,小k一时语塞,陷入了沉思:
我每天面对运行几十个爬虫,每次都是一个个文件右击运行,能不能通过命令行来运行爬虫呢?能不能通过类似
scrapy crawl xxx的方式来直接运行我的爬虫呢?
Scrapy中的命令行
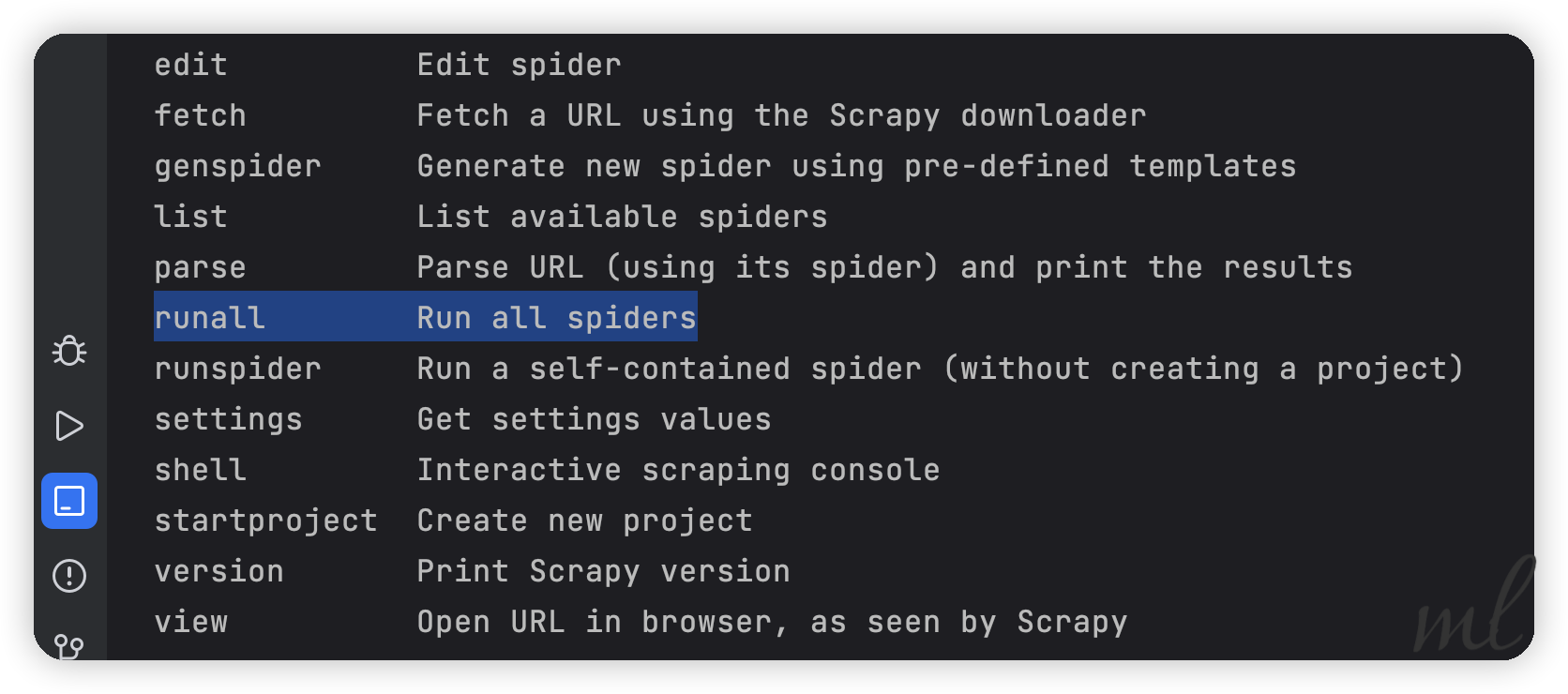
通过scrapy -h可以查看到scrapy所有的命令行:
bench Run quick benchmark test
check Check spider contracts
commands
crawl Run a spider
edit Edit spider
fetch Fetch a URL using the Scrapy downloader
genspider Generate new spider using pre-defined templates
list List available spiders
parse Parse URL (using its spider) and print the results
runspider Run a self-contained spider (without creating a project)
settings Get settings values
shell Interactive scraping console
startproject Create new project
version Print Scrapy version
view Open URL in browser, as seen by Scrapy
Use "scrapy <command> -h" to see more info about a command
命令行入口源码比较好找,一般在库的__main__.py下即可看到,scrapy的入口源码如下:
# __main__.py
from scrapy.cmdline import execute
if __name__ == '__main__':
execute()
进入execute方法中可以看到,其实scrapy中所有的命令行都是动态生成的,不仅如此,它还支持用户自定义命令行:

内置命令行
根据源码可以看到,scrapy内置了commands模块,该模块下包含了所有的命令行,比如crawl、list、shell等等,这些命令行都是通过scrapy.commands模块下的ScrapyCommand类来实现的,通过继承该类,可以实现自定义命令行。
例如:scrapy list 对应的命令行源码如下:
from scrapy.commands import ScrapyCommand
class Command(ScrapyCommand):
requires_project = True
default_settings = {'LOG_ENABLED': False}
def short_desc(self):
return "List available spiders"
def run(self, args, opts):
for s in sorted(self.crawler_process.spider_loader.list()):
print(s)
简单介绍下ScrapyCommand类中的属性:
requires_project:是否需要项目,如果为True,则在运行命令行时需要在项目目录下运行,否则会报错。crawler_process:scrapy中的核心对象,可以通过该对象来获取spider_loader、settings等等。run:命令行的主要逻辑,可以在该方法中实现命令行的主要逻辑。也是我们自定义命令行时需要重写的方法。short_desc:命令行的描述,可以通过scrapy -h查看到。long_desc:命令行的详细描述,可以通过scrapy <command> -h查看到。
自定义命令行
有了对scrapy内置命令行的了解,我们就可以自定义命令行了,比如我们想要实现一个scrapy runall命令行,通过此命令行,我可以运行项目下所有的爬虫。
可以通过如下方式实现:
# runall.py
# -*- coding: utf-8 -*-
from scrapy.commands import ScrapyCommand
class Command(ScrapyCommand):
requires_project = True
def syntax(self):
return '[options]'
def short_desc(self):
return 'Run all spiders'
def run(self, args, opts):
spider_loader = self.crawler_process.spider_loader
for spider_name in spider_loader.list():
self.crawler_process.crawl(spider_name)
self.crawler_process.start()
接下来我们需要将该命令行注册到scrapy中,我们首先新建commands包,然后将上面编写的runall.py放到该包下。
然后在项目的setting.py文件中进行修改。
# settings.py
COMMANDS_MODULE = 'PROJECT_NAME.commands'
先来看看是否注册上了:
scrapy -h
可以看到,我们的命令行已经注册上了,接下来我们就可以运行了:
scrapy runall
其他项目中的命令行
还有一个场景小k也考虑到了,就是当自己不是用scrapy搭建爬虫框架时,比如纯requests的项目中如何也可以通过命令行的方式启动爬虫呢?
我们先捋一下思路:
- 通过命令行启动:
python run.py -n spider_name - 通过
run.py文件中的main方法来启动爬虫 - 通过给定的
spider_name来获取对应的爬虫类(动态导入) - 运行爬虫
沿着这个思路,我们可以应用argparse来实现命令行的解析,然后通过__import__来动态导入爬虫类,最后运行爬虫。
此时我们可以通过命令行来启动爬虫了:
python run.py -n baidu

命令行的小升级
上面我们为了启动BaiduSpider,需要在命令行中输入python run.py -n baidu,这样的话,我觉得有点麻烦,能不能像scrapy一样,直接点运行。
这种command-script的方式,在pip package的模式下只需要setup.py中配置一下就可以了,但是我们这里是纯python项目,所以我们需要手动配置一下。
这里我巧妙的运用了alias来实现,当然我为了测试只是临时使用。
alias runspider='python run.py'
