
requests大文件上传
阅读本文,你将获得:
- requests大文件上传原理
- 大文件上传的方法
- 带进度的文件上传方法
为了更为方便的测试,我们现在本地docker搭建httpbin服务,httpbin是一个测试http请求的服务,可以用来测试各种http请求,包括文件上传。
docker run -p 8888:80 -d kennethreitz/httpbin
通过httpbin的/post接口测试文件上传,httpbin会将上传的文件返回,方便我们测试。
理解requests大文件上传原理
以往我们使用requests上传文件,都是通过files参数来上传文件,但是files参数有个缺点,就是文件会被读取到内存中,如果文件过大,会导致内存溢出。
import requests
url = 'http://localhost:8888/post'
files = {'file': open('test.txt', 'rb')} # 读取文件到内存中
r = requests.post(url, files=files)
print(r.text)
为此我们需要像requests中stream下载文件一样,使用"stream"上传文件,这样文件就不会被读取到内存中。
通过阅读requests源码,我发现当files参数有值时,会进入_encode_files方法。在这个方法里,会将文件一次性读取到内存中,再通过encode_multipart_formdata方法写入body参数。
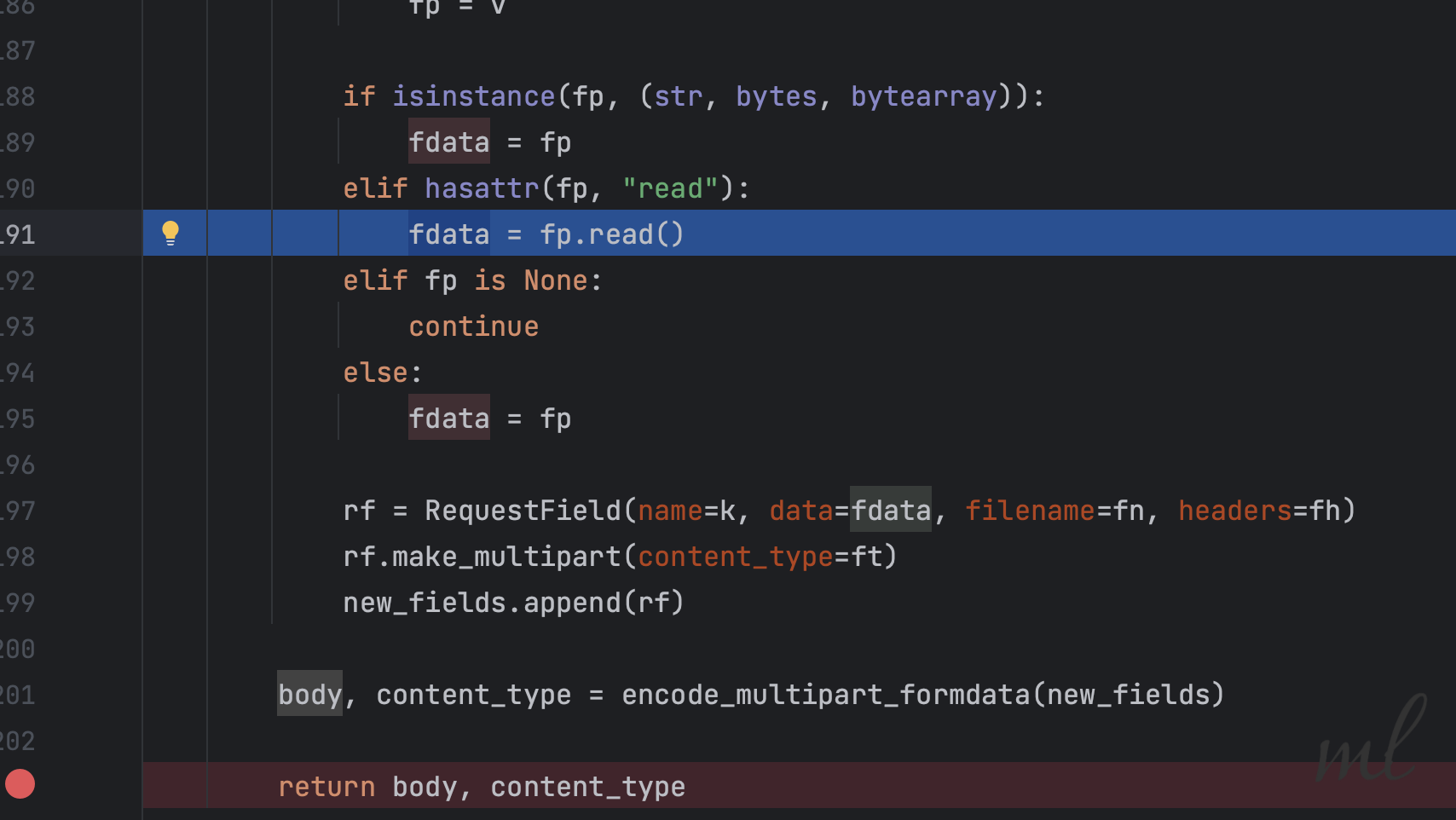
所以,我们的思考的方向就不应该使用files字段处理文件上传。当然,这句话是基于大文件的前提。
除了files字段,那就只剩data字段了,继续阅读源码后,在prepare_body方法中检测了传入的data字段,当它不满足以下条件时
is_stream = all([
hasattr(data, '__iter__'),
not isinstance(data, (basestring, list, tuple, Mapping))
])
且files字段为空时,会进入_encode_params方法,检测如果data存在read方法时,就直接返回data。
而在后续http模块中的_send_output方法会检测data是否存在read方法,如果存在就会调用read方法,将数据yield出去。

而在下游循环读取分片数据,发送sock请求。
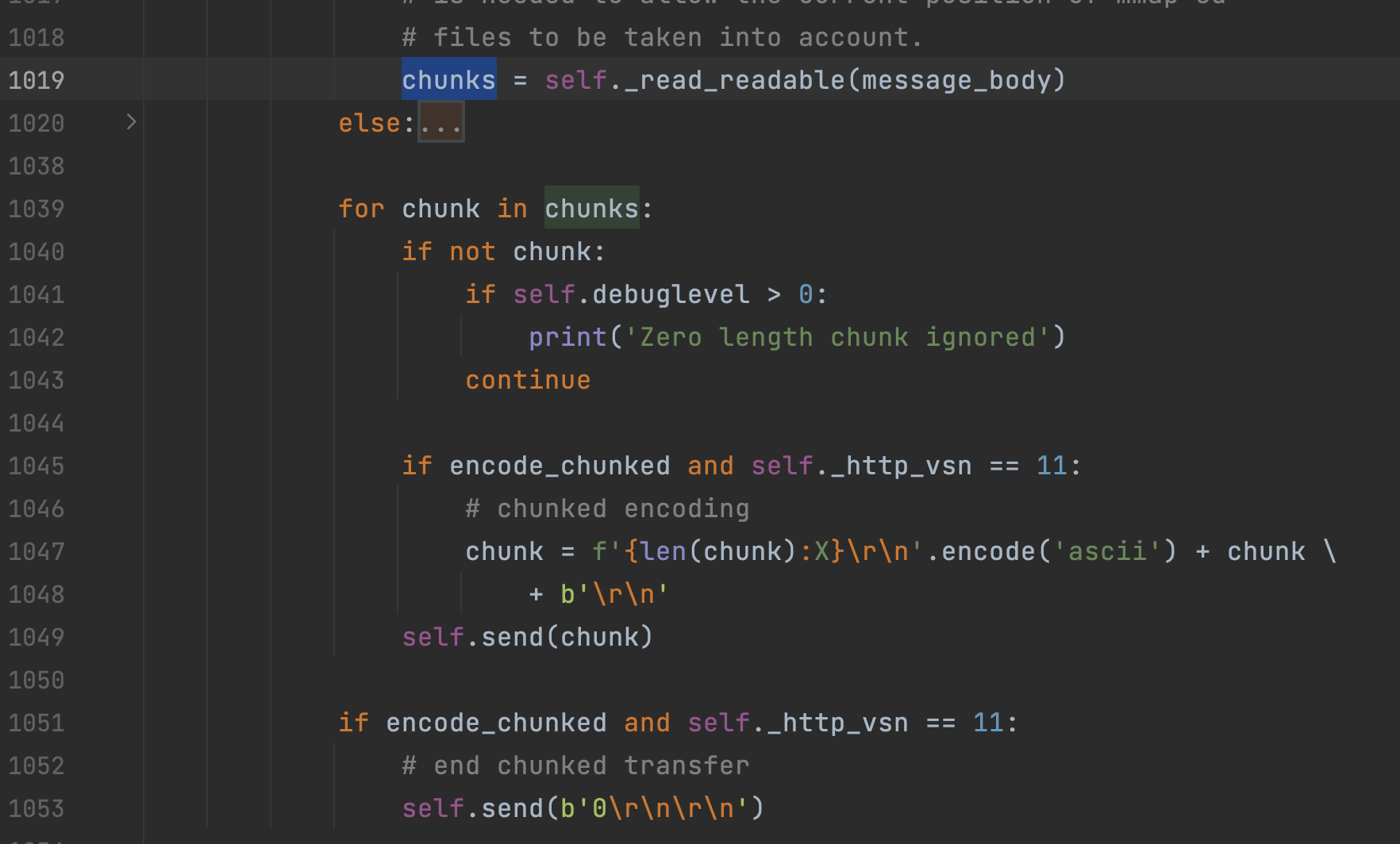
看懂了它的原理,我们只需要假模假式地构造一个data参数,让它满足read方法即可。
import requests
class File:
def __init__(self, filename):
self.filename = filename
def read(self, size=-1):
with open(self.filename, 'rb') as file:
return file.read(size)
def __len__(self):
return 100
url = 'http://localhost:8888/post'
r = requests.post(url, data=File("train_data.json"))
print(r.text)
debugger模式下,我们可以看到数据正在被分片读取,发送到sock中。
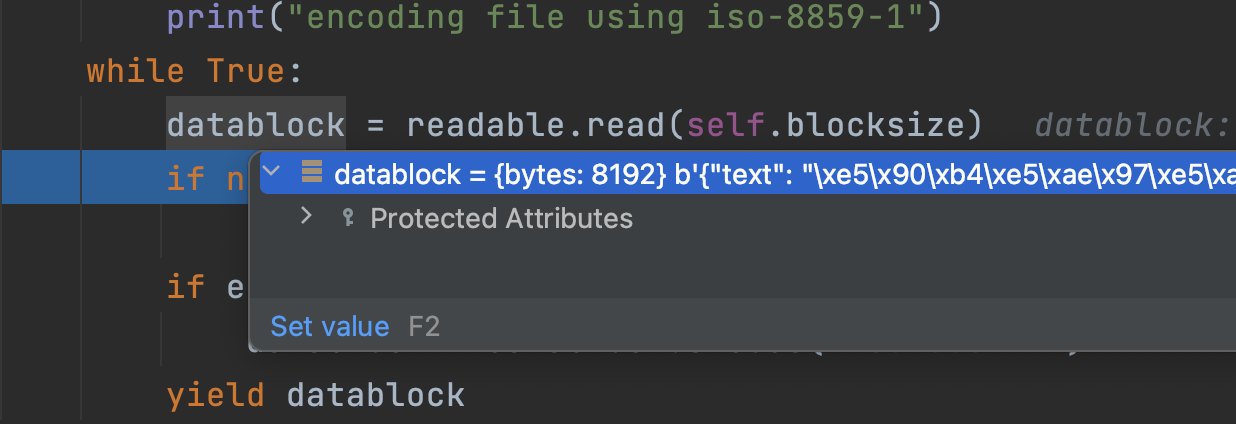

理解了原理,自己造轮子实现未免太麻烦,我们可以使用requests-toolbelt中的MultipartEncoder来实现。
使用requests-toolbelt实现大文件上传
而反观requests-toolbelt的源码,它的实现原理也是一样的。
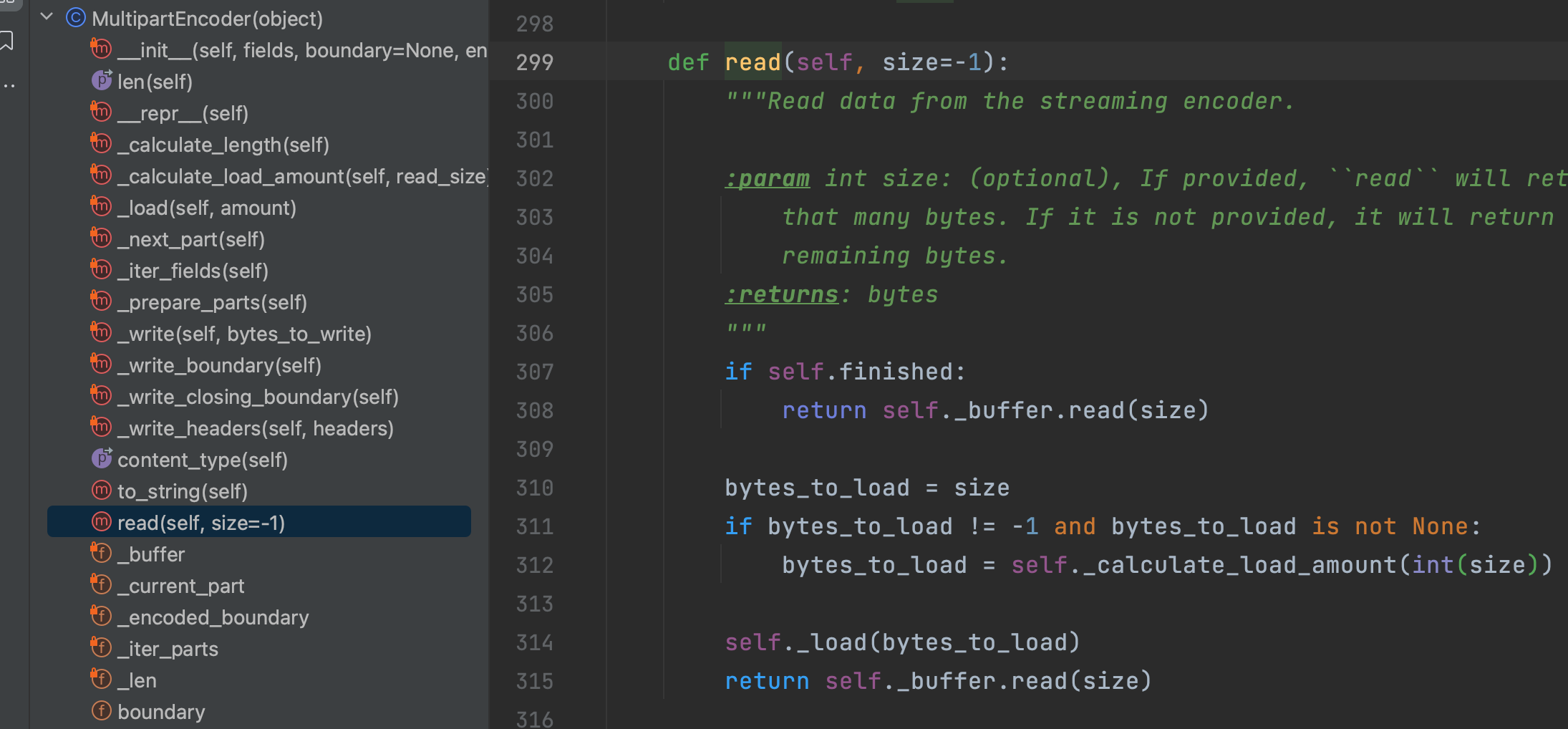
具体的代码示例文档有很多,本文不做大幅度的展示。
from requests_toolbelt import MultipartEncoder
import requests
url = 'http://127.0.0.1:8888/post'
encoder = MultipartEncoder(
fields={'file': ("train_data.json", open("train_data.json", 'rb'), 'application/octet-stream')}
)
headers = {'Content-Type': encoder.content_type}
response = requests.post(url, data=encoder, headers=headers)
response.raise_for_status()
print(response.json())
带进度的文件上传
MultipartEncoderMonitor可以通过回调函数来监控文件上传进度,我们可以通过它来实现带进度的文件上传。计算进度的方法很简单,就是当前已读取的字节数除以文件总字节数。
class MultipartEncoderMonitor(object):
...
def read(self, size=-1):
# 调用原始的read方法,读取分片数据
string = self.encoder.read(size)
# 累加已读取的字节数
self.bytes_read += len(string)
# 调用回调函数
self.callback(self)
return string
具体实现:
from requests_toolbelt import MultipartEncoder, MultipartEncoderMonitor
import requests
url = 'http://127.0.0.1:8888/post'
def callback(m):
progress = (m.bytes_read / m.len) * 100
print("\r 文件上传进度:%d%%(%d/%d)" % (progress, m.bytes_read, m.len), end=" ")
encoder = MultipartEncoder(
fields={'file': ("train_data.json", open("train_data.json", 'rb'), 'application/octet-stream')}
)
monitor = MultipartEncoderMonitor(encoder, callback)
headers = {'Content-Type': monitor.content_type}
response = requests.post(url, data=monitor, headers=headers)
response.raise_for_status()
print(response.json())
总结
本文介绍了requests大文件上传的原理,理解为何不采用files参数来直接上传文件,理解了requests是如何通过data参数来实现大文件分片读取上传的,以及如何使用requests-toolbelt实现大文件上传,以及如何实现带进度的文件上传。